







| Protein: | gi|50944495, gi|... |
| Organism: | Oryza sativa Japonica Group |
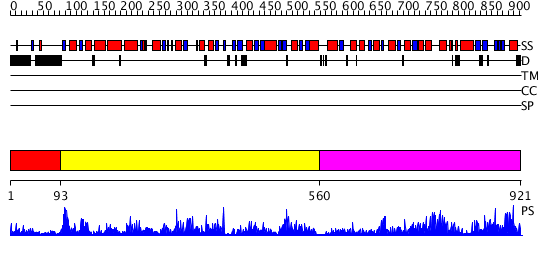
| Length: | 921 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
No multiple sequence alignment data found for gi|50944495, gi|....
|
Region A: Residues: [1-92] |
1 11 21 31 41 51
| | | | | |
1 MWSLAVASPH PAAAFAAARP RRGPRPAAAP SHRGVNPQRW RCEKTQAWSF WSSLWASDLP 60
61 GGLYGDVSKN MLKPAAAVSV EQAEASAHLP KG
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [93-559] |
1 11 21 31 41 51
| | | | | |
1 DMWSVHKFGG TCMGTSQRIQ NVADIILRDP SERKLVVVSA MSKVTDMMYN LVNKAQSRDD 60
61 SYITALDEVF EKHMAAAKDL LGGEDLARFL SQLHADVSNL KAMLRAICIA GHATESFSDF 120
121 VVGHGEIWSA QLLSFAIKKS GTPCSWMDTR EVLVVNPTGS NQVDPDYLES EKRLEKWFAR 180
181 QPAETIIATG FIASTPENIP TTLKRDGSDF SAAIIGSLVK AGQVTIWTDV DGVFSADPRK 240
241 VSEAVILSTL SYQEAWEMSY FGANVLHPRT IIPVMKYNIP IVIRNMFNIS APGTMICQQP 300
301 ANESGDLEAC VKAFATIDKL SLVNVEGTGM AGVPGTASAI FGAVKDVGAN VIMISQASSE 360
361 HSVCFAVPEK EVAAVSAALH VRFREALSAG RLSKVEVIHN CSILAAVGLK MASTPGVSAT 420
421 LFDALAKANI NVRAIAQGCS EYNITVVLKQ EDCVRALRAA HSRFFLS
|
| Detection Method: | |
| Confidence: | 116.0 |
| Match: | 3c1mA |
| Description: | No description for 3c1mA was found. |
|
Region A: Residues: [560-921] |
1 11 21 31 41 51
| | | | | |
1 KTTLAVGIIG PGLIGRTLLN QLKDQAAVLK ENMNIDLRVM GITGSRTMVL SDTGIDLAHW 60
61 KEQLQTEAEP ANLDKFVDHL SENQLFPNRV LVDCTADTSV ASHYYDWLKK GIHVITPNKK 120
121 ANSGPLDKYL KLRTLQRASY THYFYEATVG AGLPIISTLR GLLETGDKIL RIEGIFSGTL 180
181 SYIFNNFEGT RAFSDVVSEA KEAGYTEPDP RDDLSGTDVA RKVIILARES GLKLELSDIP 240
241 VRSLVPEALR SCSTADEYMQ KLPSFDQDWA RESKDAEAAG EVLRYVGVVD LVNKEGQVEL 300
301 RRYKKDHPFA QLSGSDNIIA FTTSRYKEQP LIVRGPGAGA EVTAGGVFSD ILRLASYLGA 360
361 PS
|
| Detection Method: | |
| Confidence: | 65.39794 |
| Match: | 1ebfA |
| Description: | Homoserine dehydrogenase |
Matching Structure (courtesy of the PDB): |
|